1.2. What can’t be done with CMake¶
CMake has its strengths and weaknesses. Most of the drawbacks mentioned here can be worked around by using approaches that may differ from your normal workflow, yet still reach the end goal. Try to look at them from another angle; think of the picture as a whole and remember that the advantages definitely outweigh the disadvantages.
1.2.1. Language/syntax¶
This is probably the first thing you will be hit with. The CMake language is not something you can compare with what you have likely used before. There are no classes, no maps, no virtual functions or lambdas. Even such tasks like “parse the input arguments of a function” and “return result from a function” are quite tricky for the beginners. CMake is definitely not a language you want to try to experiment with implementation of red-black tree or processing JSON responses from a server. But it does handle regular development very efficiently and you probably will find it more attractive than XML files, autotools configs or JSON-like syntax.
Think about it in this way: if you want to do some nasty non-standard thing then probably you should stop. If you think it is something important, then it might be quite useful for other CMake users too. In this case you need to think about implementing new feature in CMake itself. CMake is open-source project written in C++, and additional features are always being introduced. You can also discuss any problems in the CMake mailing-list to see how you can help with improving the current state.
CMake mailing list
1.2.2. Affecting workflow¶
This might sound contradictory to the statement that you can keep using your favorite tools, but it’s not. You still can work with your favorite IDE, but you must remember that CMake is now “in charge”.
Imagine you have C++ header version.h
generated automatically by some script from template version.h.in. You see
version.h file in your IDE, you can update it and run build and new variables
from version.h will be used in binary, but you should never do it since
you know that source is actually version.h.in.
Similarly, when you use CMake - you should never
update your build configuration directly in the IDE. Instead, you have to remember that
any target files generated from CMakeLists.txt and all your project additions made
directly in the IDE will be lost next time you run CMake.
Wrong workflow:
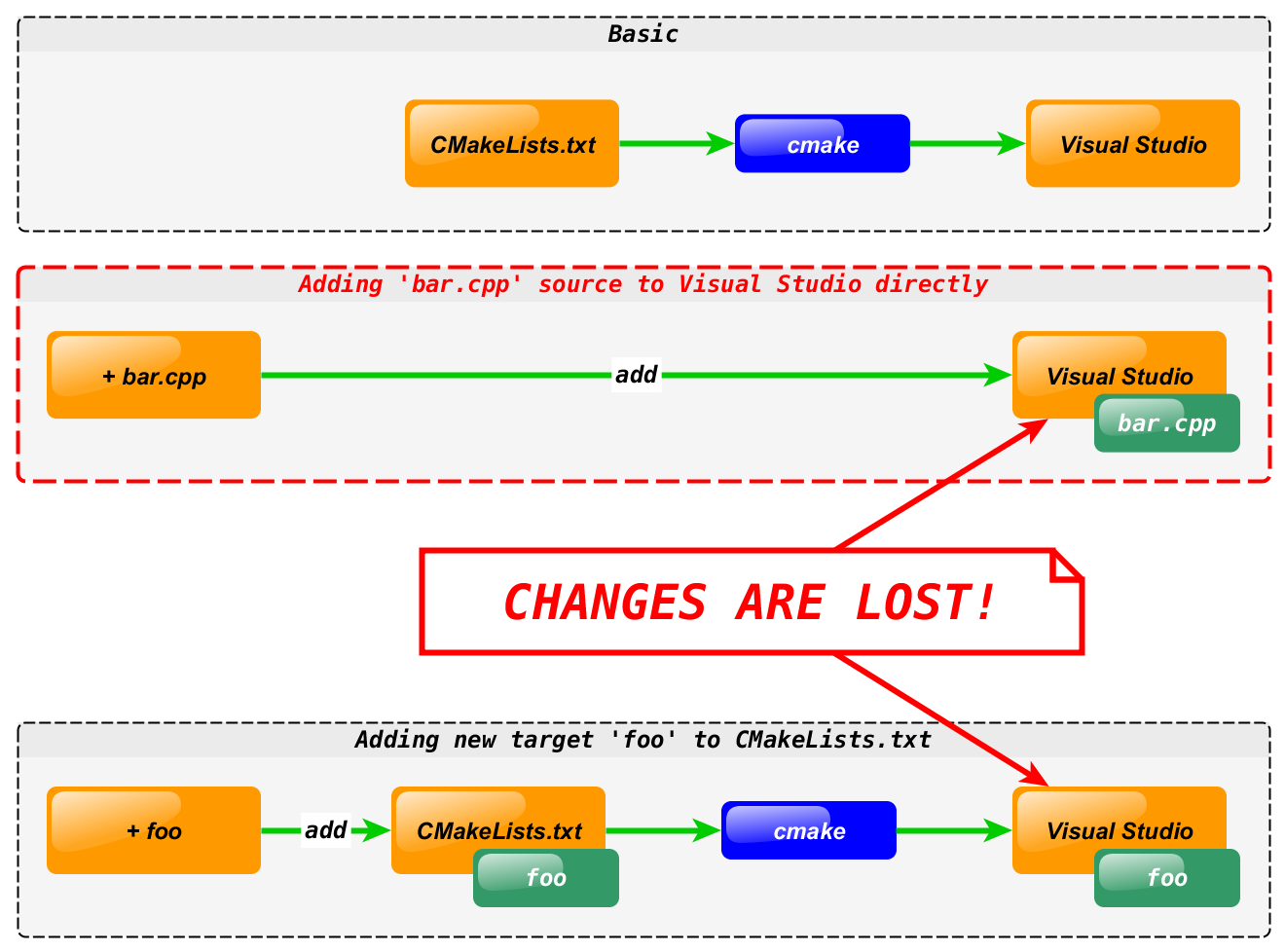
Correct workflow:
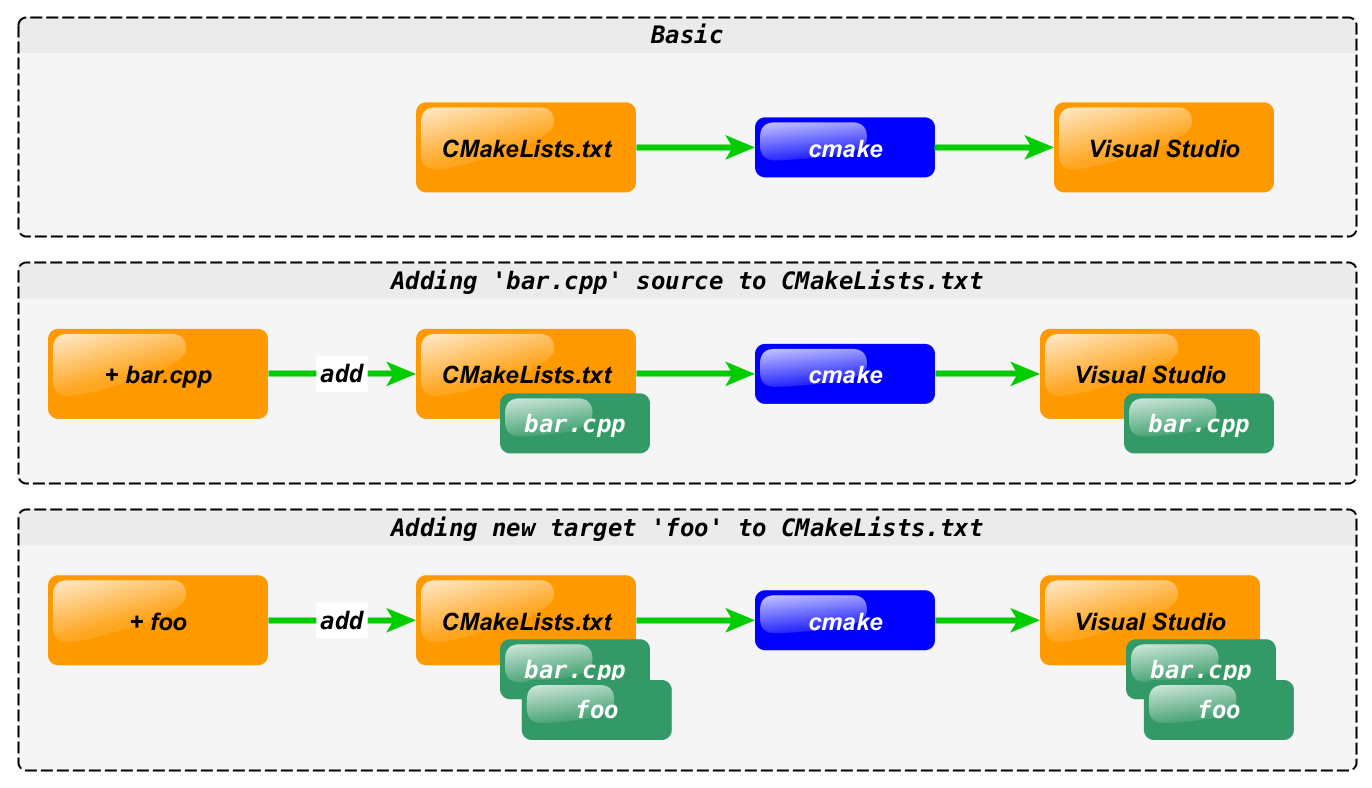
It’s not enough to know that if you want to add a new library to your
Visual Studio solution you can do:
You have to know that this must instead be done by adding a new
add_library command to CMakeLists.txt.
1.2.3. Incomplete functionality coverage¶
There are some missing features in CMake. Mapping of
CMake functionality <-> native build tool functionality
is not always bijective. Often this can be worked around by generating different
native tool files from the same CMake code. For example, it’s possible using
autotools to create two versions of a library
(shared + static) in a single run.
However, this may affect performance, or be outright impossible for other platforms
(e.g., Windows). With CMake, you can generate two versions of a
project from a single CMakeLists.txt file: one each for shared and static
variants, effectively running generate/build twice.
With Visual Studio you can have two variants, x86 and x64, in one solution
file. With CMake you have to generate project twice:
once with Visual Studio generator and one more time with Visual Studio Win64
generator.
Similarly with Xcode. In general CMake can’t mix two different
toolchains (at least for now) so it’s not possible to generate an Xcode
project with iOS and OSX targets—again, just generate code for each
platform independently.
1.2.4. Unrelocatable projects¶
Internally, CMake saves the full paths to each of the sources,
so it’s not possible to generate a project then share it between several developers.
In other words, you can’t be “the CMake person” who will generate separate projects for
those who use Xcode and those who use Visual Studio. All developers in the team should be
aware of how to generate projects using CMake. In practice it means they have
to know which CMake arguments to use, some basic examples being
cmake -H. -B_builds -GXcode and cmake -H. -B_builds "-GVisual Studio 12 2013"
for Xcode and Visual Studio, respectively. Additionally, they must understand the
changes they must make in their workflow. As a general rule, developers should make an effort to learn the tools
used in making the code they wish to utilize. Only when providing an end product to users is it
your responsibility to generate user-friendly installers like *.msi instead of
simply providing the project files.
CMake documentation
Even if support for relative paths will be re-implemented in the future, each developer in the team should have CMake installed, as there are other tasks which CMake automatically takes care of that may be done incorrectly if done manually. A few examples are:
The automatic detection of changes to
CMakeLists.txtand subsequent regeneration of the source tree.The inclusion of custom build steps with the built-in scripting mode.
For doing internal stuff like searching for installed dependent packages
TODO
Link to relocatable packages